Date: 29.08.2025
ROCm PyTorch BitsAndBytes Mistral Test
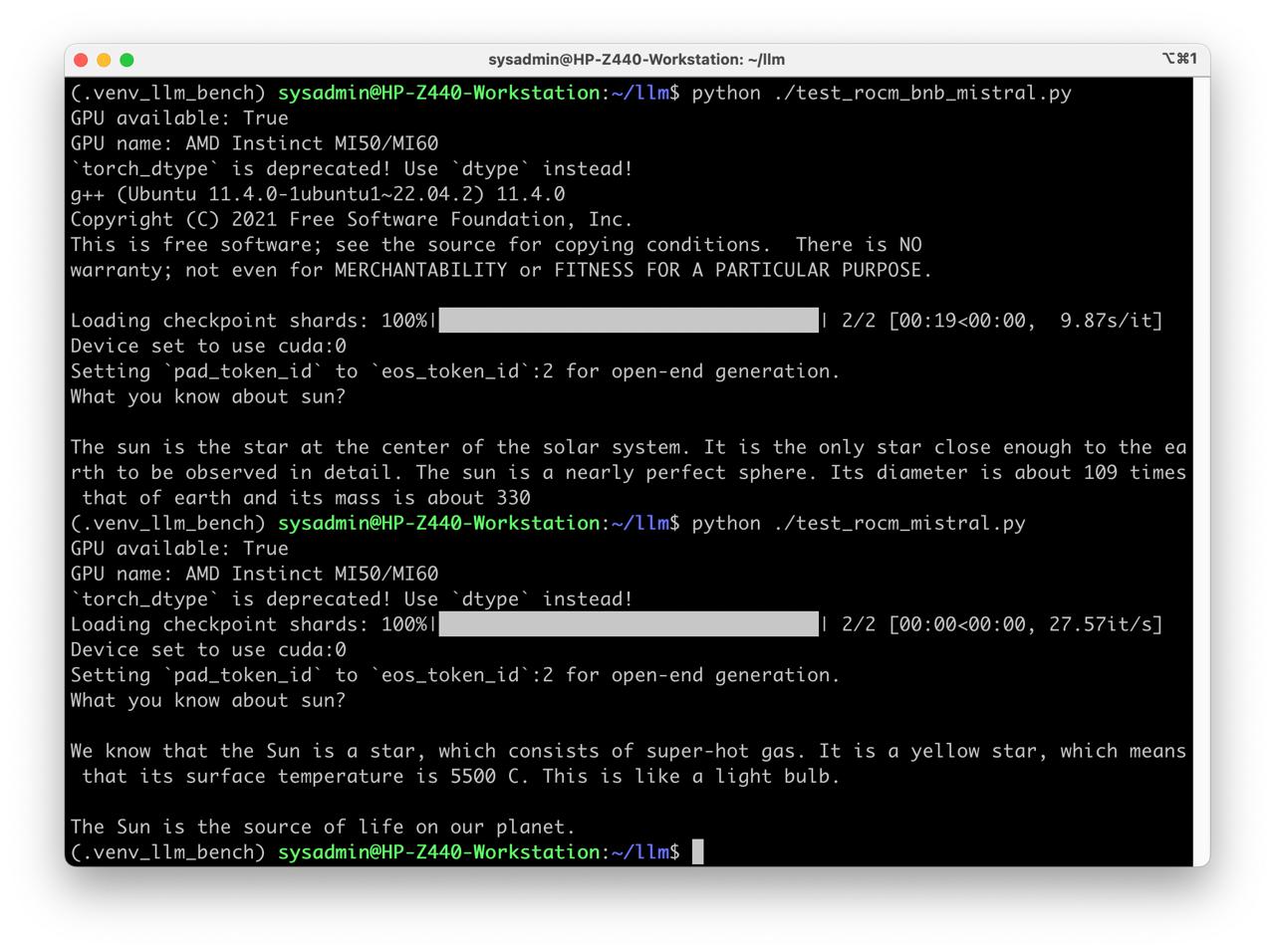
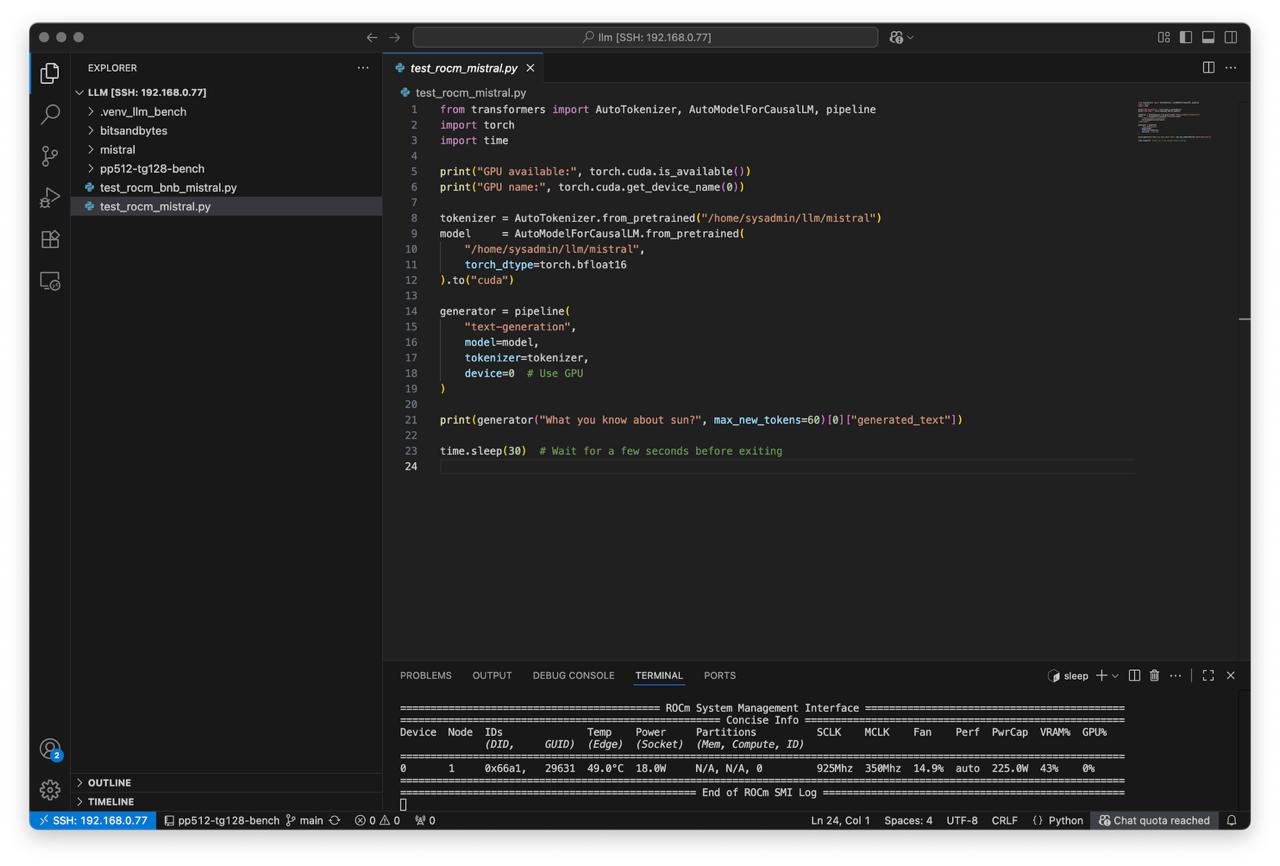
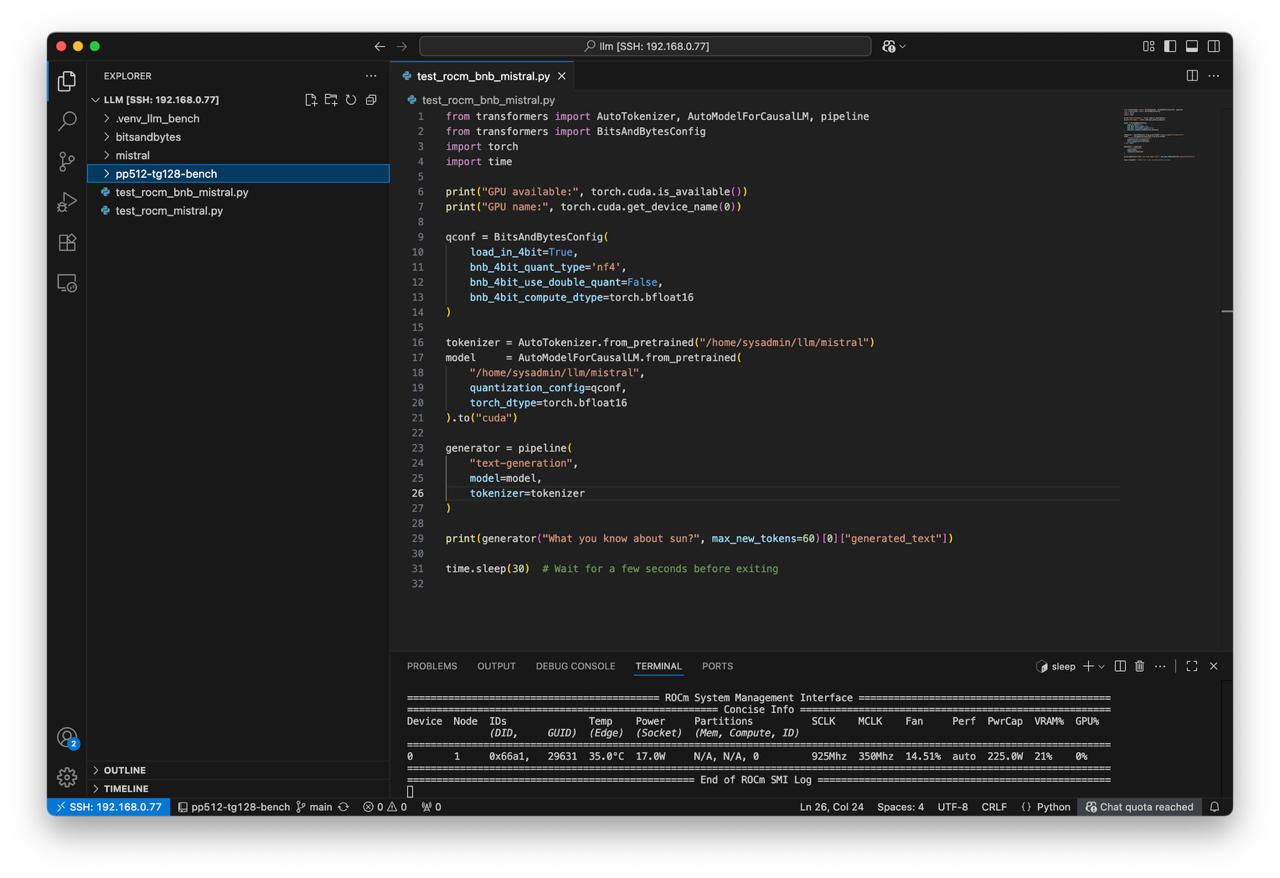
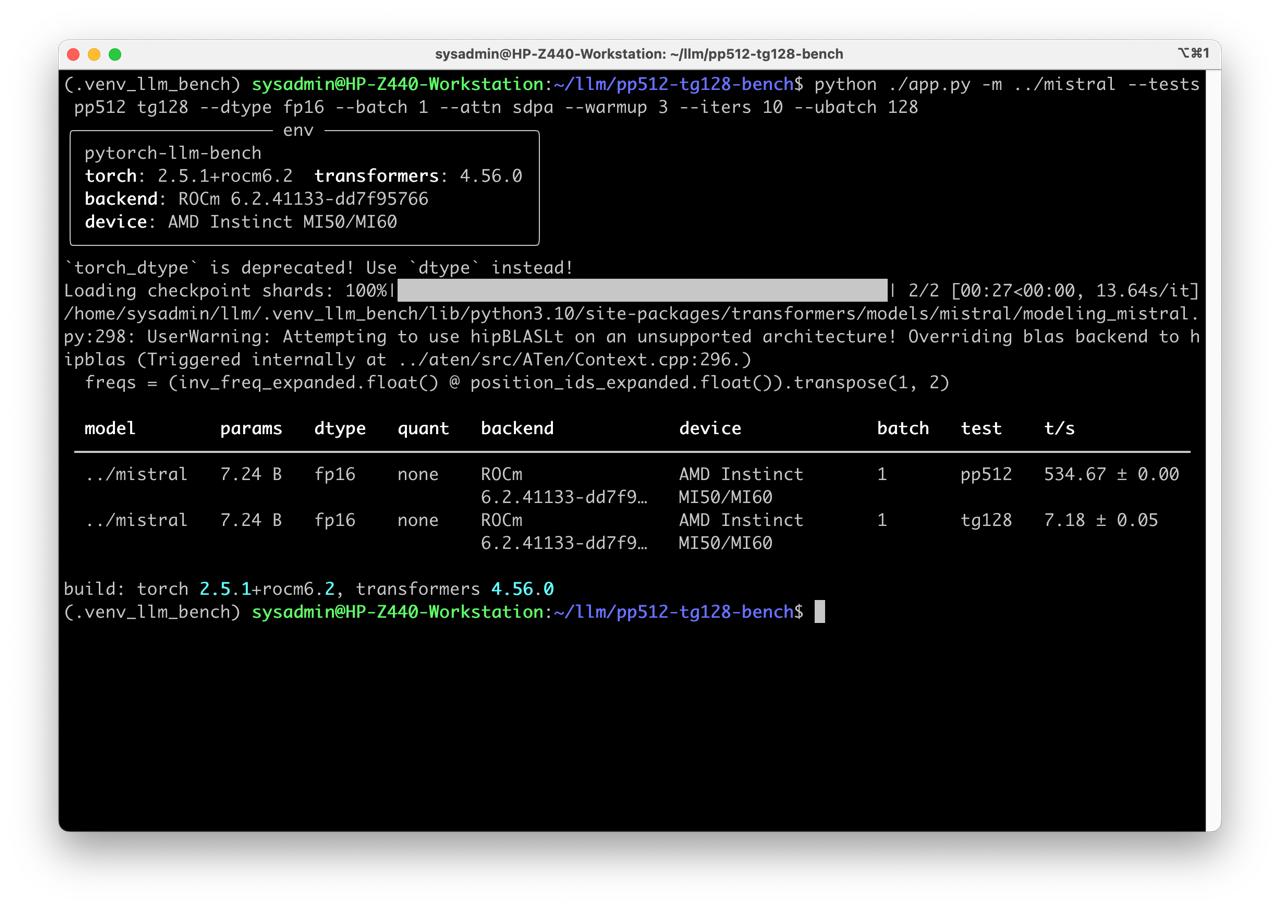
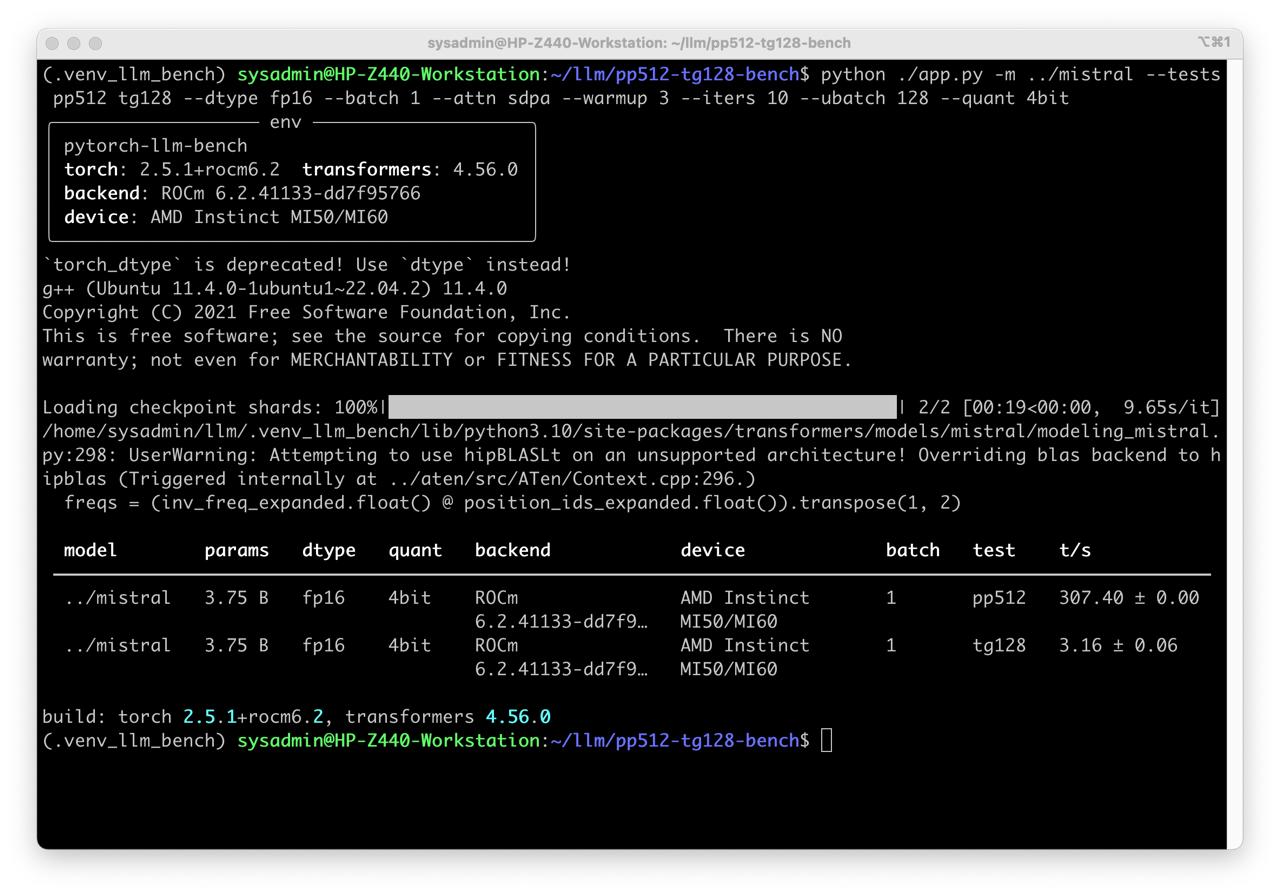
Table of Contents
Overview
Requirments
- AMD Mi50 32Gb VRAM
- Workstation 40 GB RAM, 500GB SSD, 750W Power supply
- Ubuntu 22.04 LTS
- Python 3.10
Instructions
TESTs
Preapre python environment for ROCm + PyTorch + BitsAndBytes:
- Check PyTorch installation
python3 -c "import torch; print(torch.__version__); print(torch.cuda.is_available()); print(torch.version.hip);print(torch.cuda.get_device_name(0));"
- Check BitsAndBytes installation
python -m bitsandbytes
Get the Mistral
git lfs install
git clone https://huggingface.co/mistralai/Mistral-7B-v0.1 mistral
Create script test_rocm_mistral.py:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
import time
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_path = "/home/sysadmin/llm/mistral"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16
).to("cuda")
generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
device=0 # Use GPU
)
print(generator("What you know about sun?", max_new_tokens=60)[0]["generated_text"])
time.sleep(30) # Wait for a few seconds before exiting
Create script test_rocm_bnb_mistral.py:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from transformers import BitsAndBytesConfig
import torch
import time
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_path = "/home/sysadmin/llm/mistral"
qconf = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=False,
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=qconf,
torch_dtype=torch.bfloat16
).to("cuda")
generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer
)
print(generator("What you know about sun?", max_new_tokens=60)[0]["generated_text"])
time.sleep(30) # Wait for a few seconds before exiting
Run test
Check
rocm-smiduring each testwhile true; do rocm-smi; sleep 1; done
- Without quantization
python ./test_rocm_mistral.py
- With quantization
python ./test_rocm_bnb_mistral.py
Benchmark
Prepare benchmark pp512 tg128 PyTorch pp512 and tg128 LLM Benchmark
Run test
Check
rocm-smiduring each testwhile true; do rocm-smi; sleep 1; done
- Without quantization
python ./app.py -m ../mistral --tests pp512 tg128 --dtype fp16 --batch 1 --attn sdpa --warmup 3 --iters 10 --ubatch 128
- With quantization
python ./app.py -m ../mistral --tests pp512 tg128 --dtype fp16 --batch 1 --attn sdpa --warmup 3 --iters 10 --ubatch 128 --quant 4bit