Date: 27.08.2025
PyTorch pp512 and tg128 LLM Benchmark
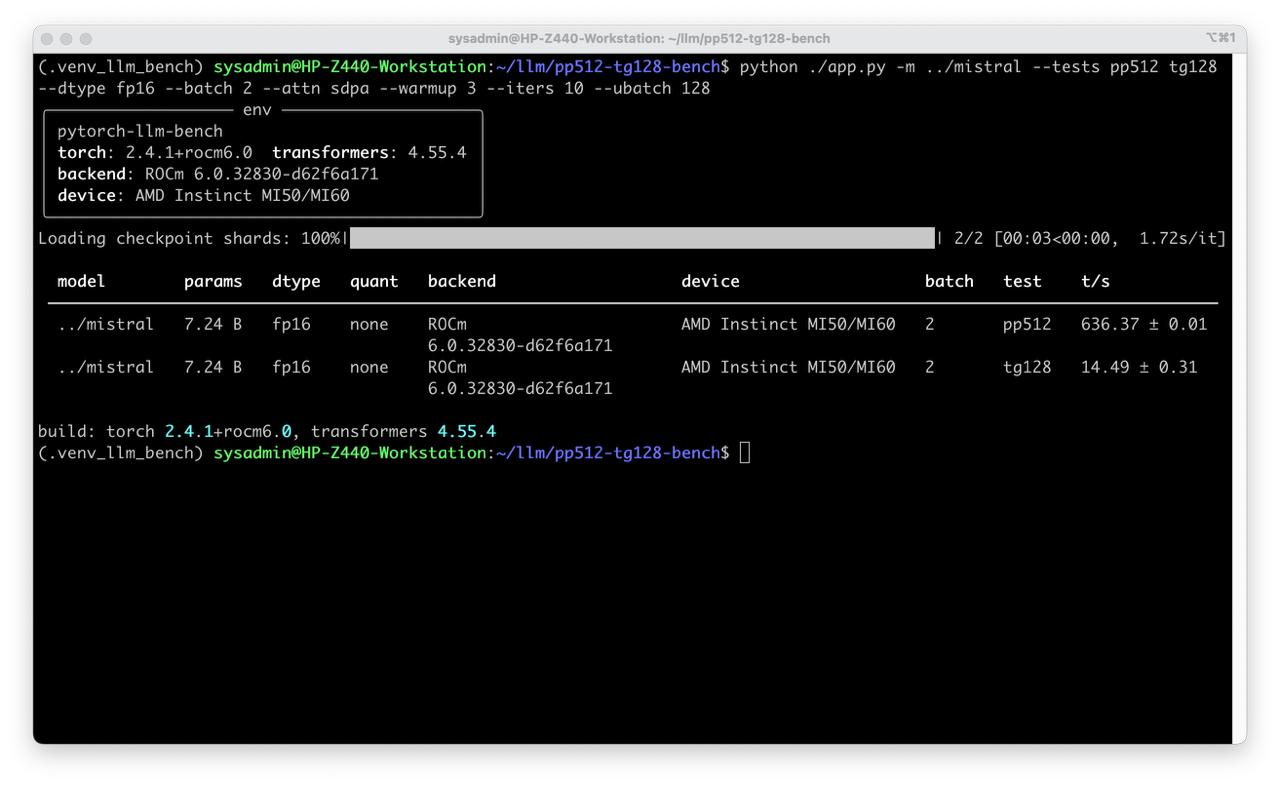
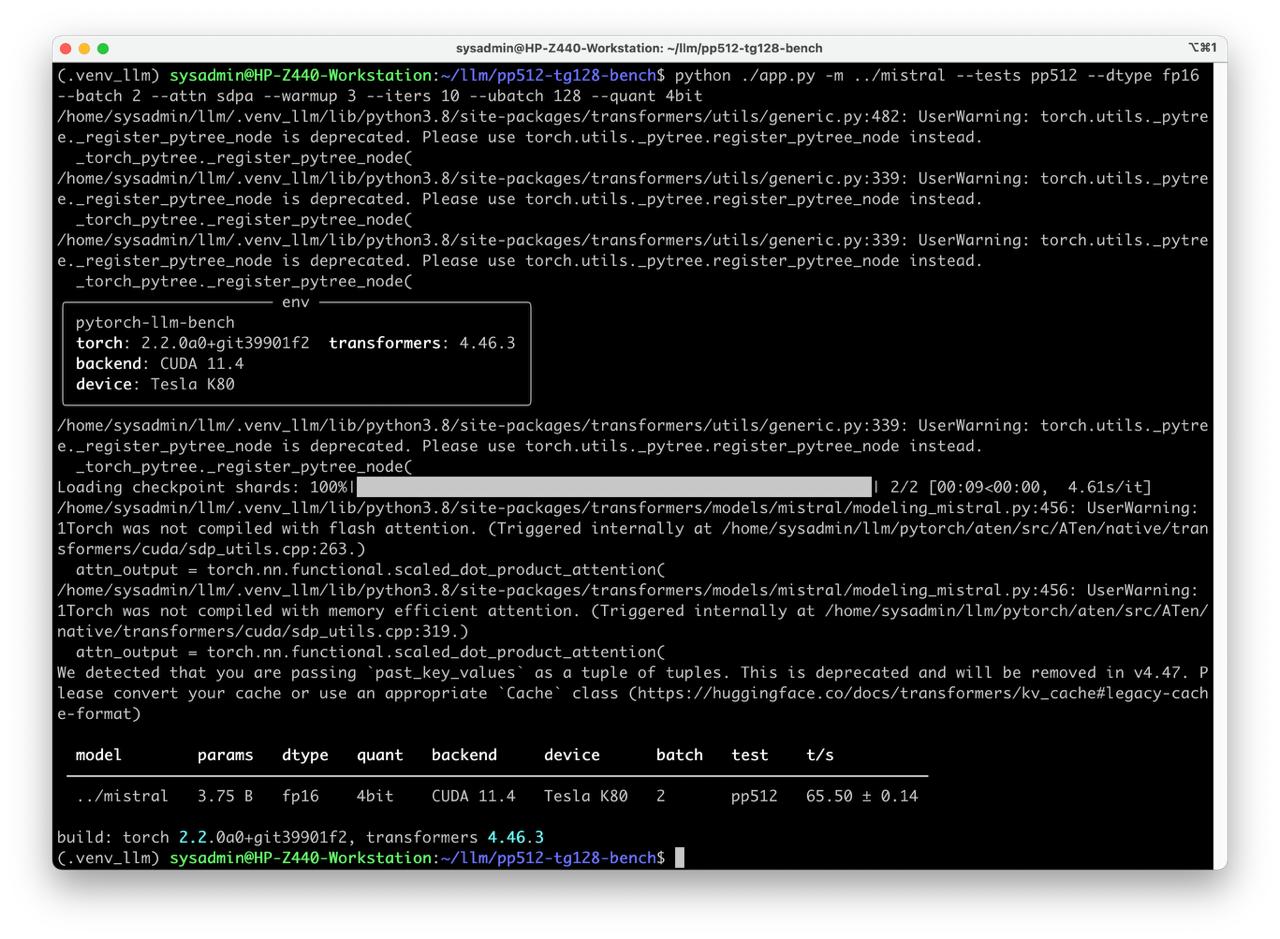
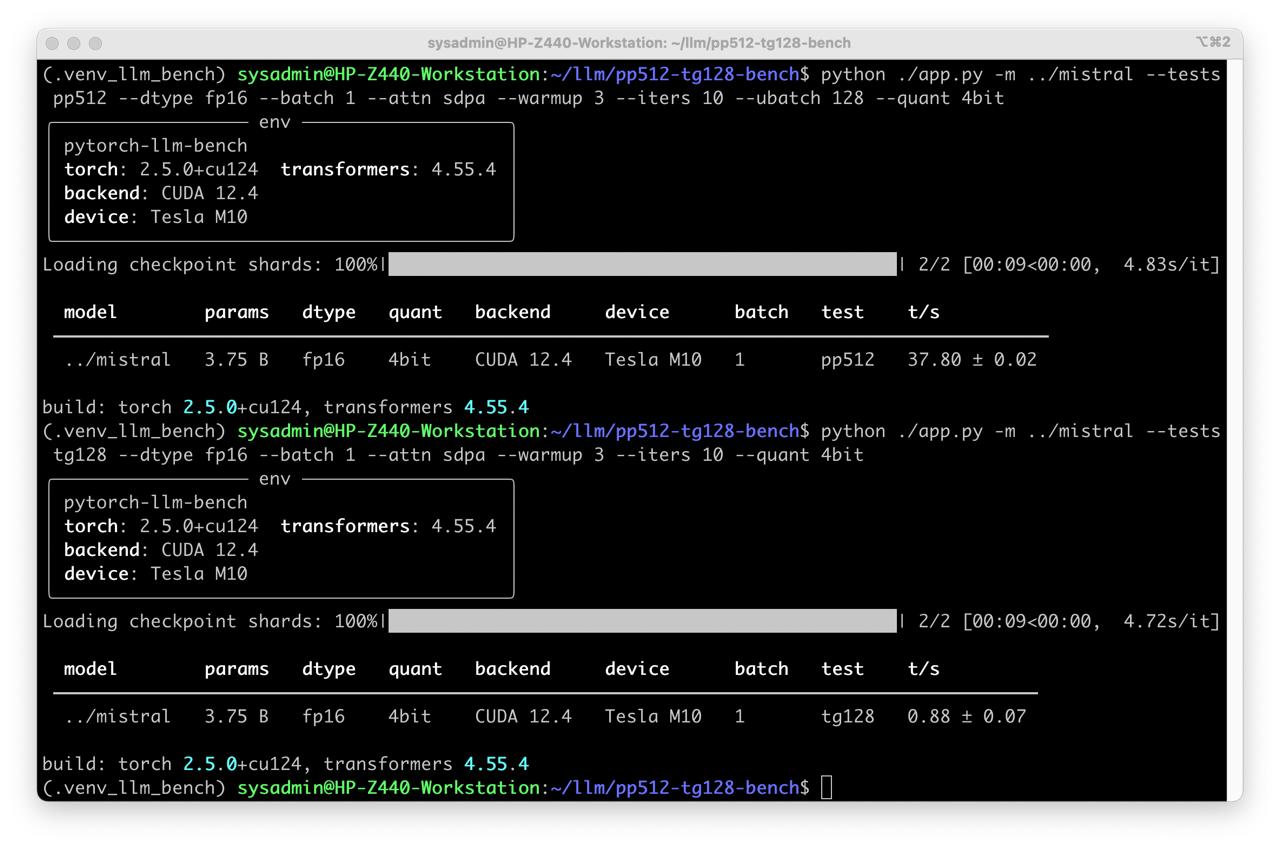
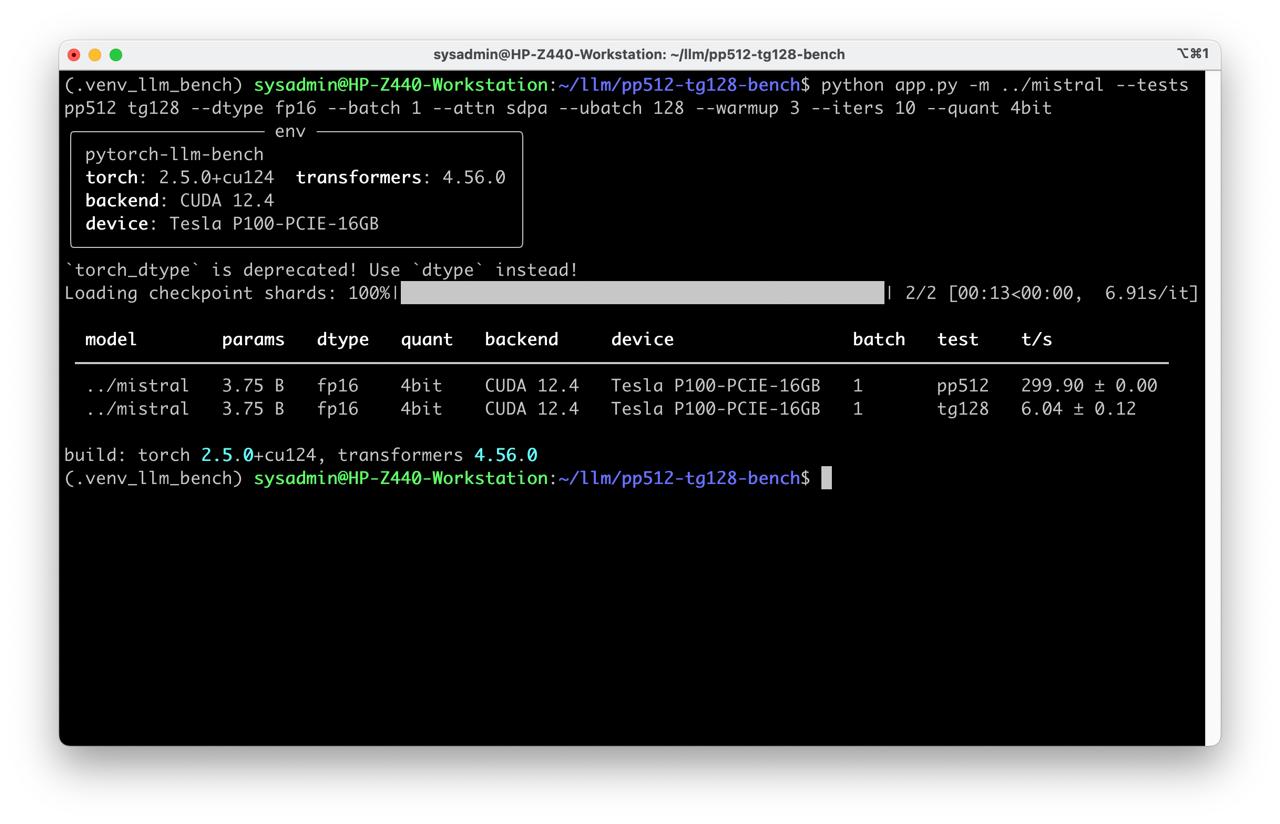
Table of Contents
Overview
What is this project about?
pp512-tg128-benchis a lightweight, reproducible benchmark suite for PyTorch in different GOU.- The code is modular model loading, GPU detection, data prep, tests, timing, and terminal rendering are separated for easy maintenance.
How the tests work (two test cases)
pp512— Prompt Processing (prefill)- Measures the speed of a single forward pass over a random prompt of 512 tokens for a batch
B. - Reports tokens/sec computed as
(B × 512) / median_time. - Reflects compute-bound throughput (big GEMMs / SDPA). Sensitive to attention kernels (SDPA/FA2), dtype (FP16/BF16), and tensor-core/matrix-core performance.
- Supports optional microbatching (
--ubatch) to emulate llama.cpp’sn_ubatchbehavior (grows KV cache chunk-by-chunk).
- Measures the speed of a single forward pass over a random prompt of 512 tokens for a batch
tg128— Text Generation (decode)- Measures the speed of generating 128 new tokens, one token at a time, using KV cache initialized by a short prefill.
- Reports tokens/sec computed as
(B × 128) / median_timeof the decode loop only (prefill isn’t counted). - Reflects latency & memory-bound behavior: frequent small matmuls, KV reads/writes, and cache layout efficiency. Often stresses memory bandwidth/latency more than raw FLOPs.
Implementation notes:
- Inputs for
pp*are random token ids with special tokens filtered out; the first token is set to BOS for consistency.- Tests run multiple iterations with warmup; the table shows
t/sand the ± std over iterations.
Applicability (what you can benchmark)
- Compare PyTorch inference performance across different GPUs and stacks: NVIDIA, AMD
- Evaluate how attention implementation affects speed:
sdpa,eager, orflash_attention_2(if available). - Quantify impact of precision/quantization (FP16/BF16 vs. 4-bit via bitsandbytes, where supported).
- Track improvements/regressions across driver/toolkit versions (CUDA/ROCm), PyTorch/Transformers versions.
Required Mistral 7b
Test environment
- AMD Mi50 32Gb VRAM
- Workstation 40 GB RAM, 200GB SSD, 750W Power supply
- Ubuntu 24.04 LTS
- Docker CE
Instructions
Preparation
Create virtualenv
- For AMD ROCm 6
mkdir -p ~/llm && cd ~/llm
python3 -m venv .venv_llm_bench
source ./.venv_llm_bench/bin/activate
python -m pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.0
pip install "transformers>=4.41" accelerate einops rich
- For NVIDIA CUDA 12
mkdir -p ~/llm && cd ~/llm
python3 -m venv .venv_llm_bench
source ./.venv_llm_bench/bin/activate
python -m pip install --upgrade pip
pip install "torch==2.5.0" "torchvision==0.20.0" "torchaudio==2.5.0" --index-url https://download.pytorch.org/whl/cu124
pip install "bitsandbytes==0.44.1"
pip install "transformers>=4.41" accelerate einops rich
- Check pytorch
python3 -c "import torch; print(torch.__version__); print(torch.cuda.is_available());print(torch.cuda.get_device_name(0));"
Get the Mistral
git lfs install
git clone https://huggingface.co/mistralai/Mistral-7B-v0.1 mistral
Get benchmark source code
git clone https://github.com/llmlaba/pp512-tg128-bench.git
Run test
- Without quantization
python ./app.py -m ../mistral --tests pp512 tg128 --dtype fp16 --batch 1 --attn sdpa --warmup 3 --iters 10 --ubatch 128
- With quantization
python ./app.py -m ../mistral --tests pp512 tg128 --dtype fp16 --batch 1 --attn sdpa --warmup 3 --iters 10 --ubatch 128 --quant 4bit
Enjoy the result
All project avalible on github