Date: 30.08.2025
Stable Diffusion v1.5 ROCm PyTorch Test

Requirments
- AMD Mi50/MI100 32Gb VRAM
- Workstation 40 GB RAM, 200GB SSD, 750W Power supply
- Ubuntu 22.04
- Python 3.10
My test environment: HP Z440 + AMD Mi50
TESTs
Preapre python environment for ROCm + PyTorch + BitsAndBytes:
- Check PyTorch installation
python3 -c "import torch; print(torch.__version__); print(torch.cuda.is_available()); print(torch.version.hip);print(torch.cuda.get_device_name(0));"
- Check BitsAndBytes installation
python -m bitsandbytes
Get the StableDiffusion 1.5
git lfs install
git clone https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5 sd1.5
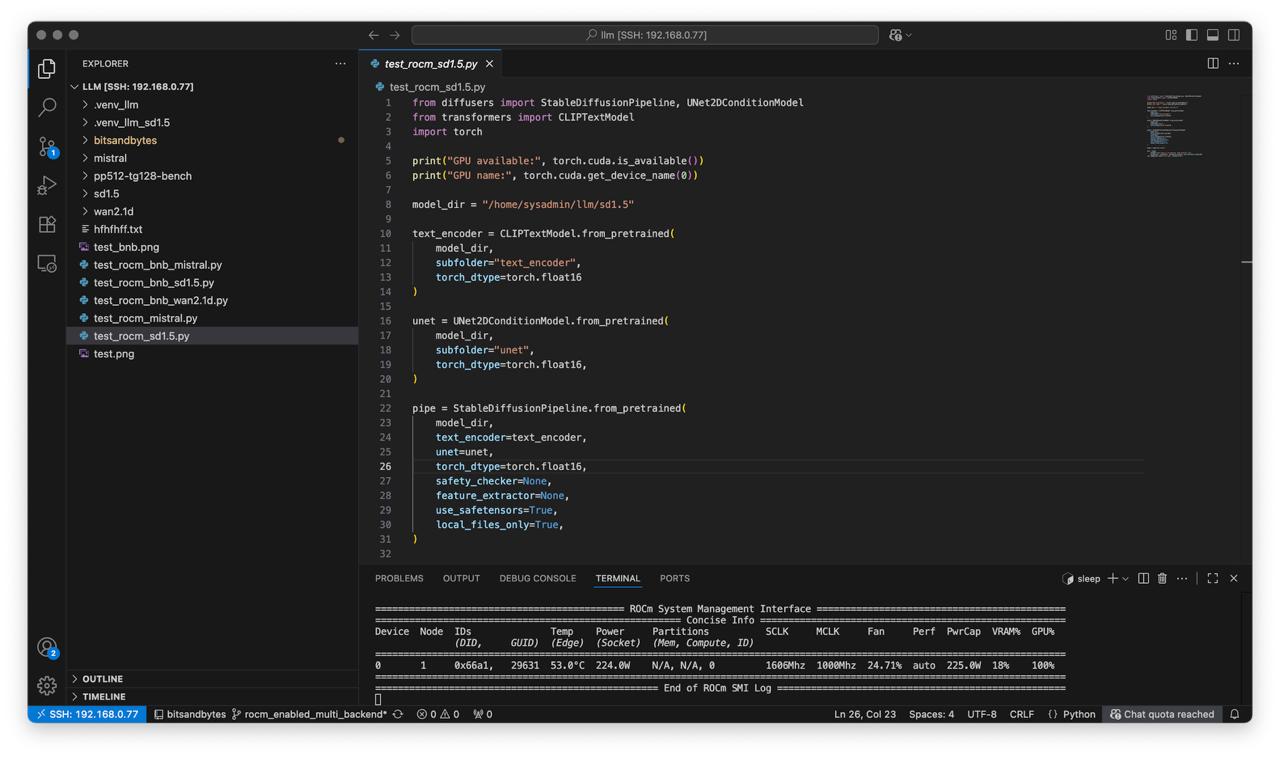
Create script test_rocm_sd1.5.py:
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
from transformers import CLIPTextModel
import torch
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_dir = "/home/sysadmin/llm/sd1.5"
text_encoder = CLIPTextModel.from_pretrained(
model_dir,
subfolder="text_encoder",
torch_dtype=torch.float16
)
unet = UNet2DConditionModel.from_pretrained(
model_dir,
subfolder="unet",
torch_dtype=torch.float16,
)
pipe = StableDiffusionPipeline.from_pretrained(
model_dir,
text_encoder=text_encoder,
unet=unet,
torch_dtype=torch.float16,
safety_checker=None,
feature_extractor=None,
use_safetensors=True,
local_files_only=True,
)
pipe = pipe.to("cuda")
out = pipe(
prompt="ford focus 3 on parking, high quality, 8k",
height=512, width=512, guidance_scale=9, num_inference_steps=80)
out.images[0].save("test.png", format="PNG")
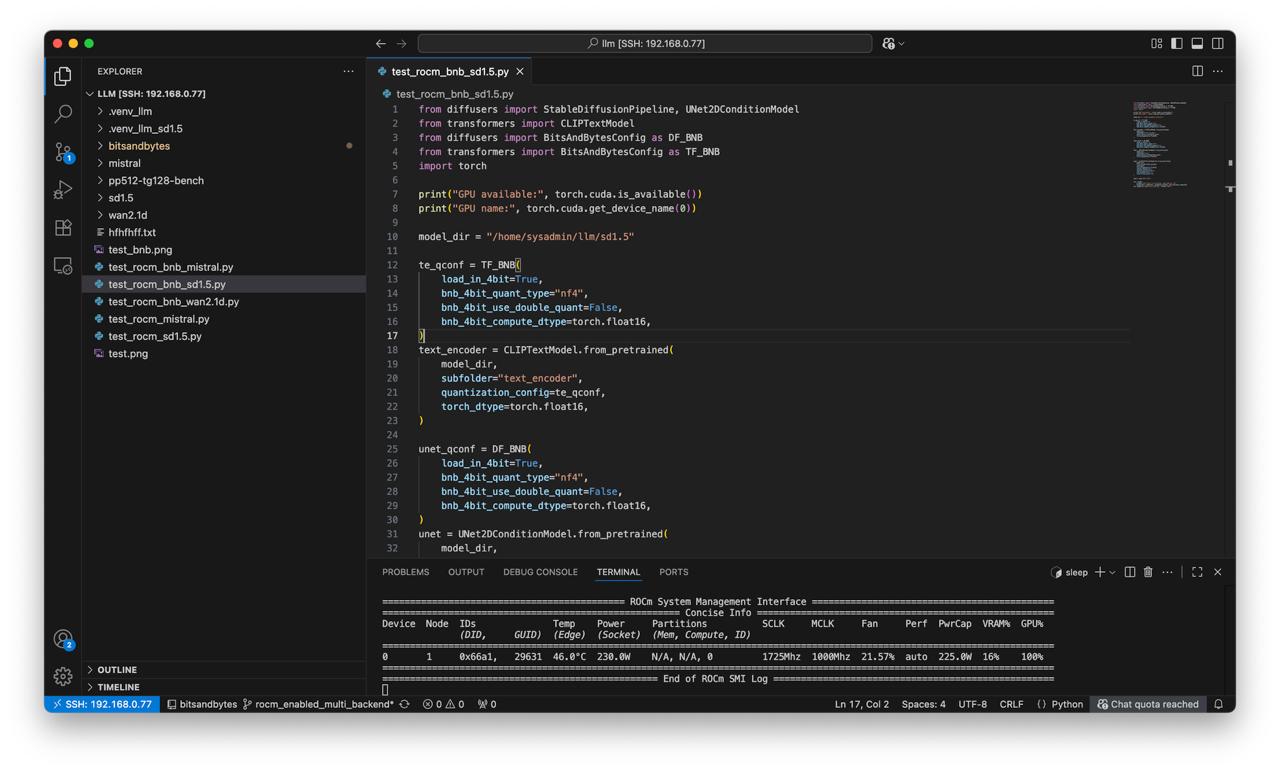
Create script test_rocm_bnb_sd1.5.py:
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
from transformers import CLIPTextModel
from diffusers import BitsAndBytesConfig as DF_BNB
from transformers import BitsAndBytesConfig as TF_BNB
import torch
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_dir = "/home/sysadmin/llm/sd1.5"
te_qconf = TF_BNB(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=False,
bnb_4bit_compute_dtype=torch.float16,
)
text_encoder = CLIPTextModel.from_pretrained(
model_dir,
subfolder="text_encoder",
quantization_config=te_qconf,
torch_dtype=torch.float16,
)
unet_qconf = DF_BNB(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=False,
bnb_4bit_compute_dtype=torch.float16,
)
unet = UNet2DConditionModel.from_pretrained(
model_dir,
subfolder="unet",
quantization_config=unet_qconf,
torch_dtype=torch.float16,
)
pipe = StableDiffusionPipeline.from_pretrained(
model_dir,
text_encoder=text_encoder,
unet=unet,
torch_dtype=torch.float16,
safety_checker=None,
feature_extractor=None,
use_safetensors=True,
local_files_only=True,
)
pipe = pipe.to("cuda")
out = pipe(
prompt="ford focus 3 on parking, high quality, 8k",
height=512, width=512, guidance_scale=9, num_inference_steps=80)
out.images[0].save("test_bnb.png", format="PNG")
Run test
Check
rocm-smiduring each testwhile true; do rocm-smi; sleep 1; done
- Without quantization
python ./test_rocm_sd1.5.py
- With quantization
python ./test_rocm_bnb_sd1.5.py