Date: 27.12.2025
Stable Diffusion 1.5 vs 2.0 vs XL Test

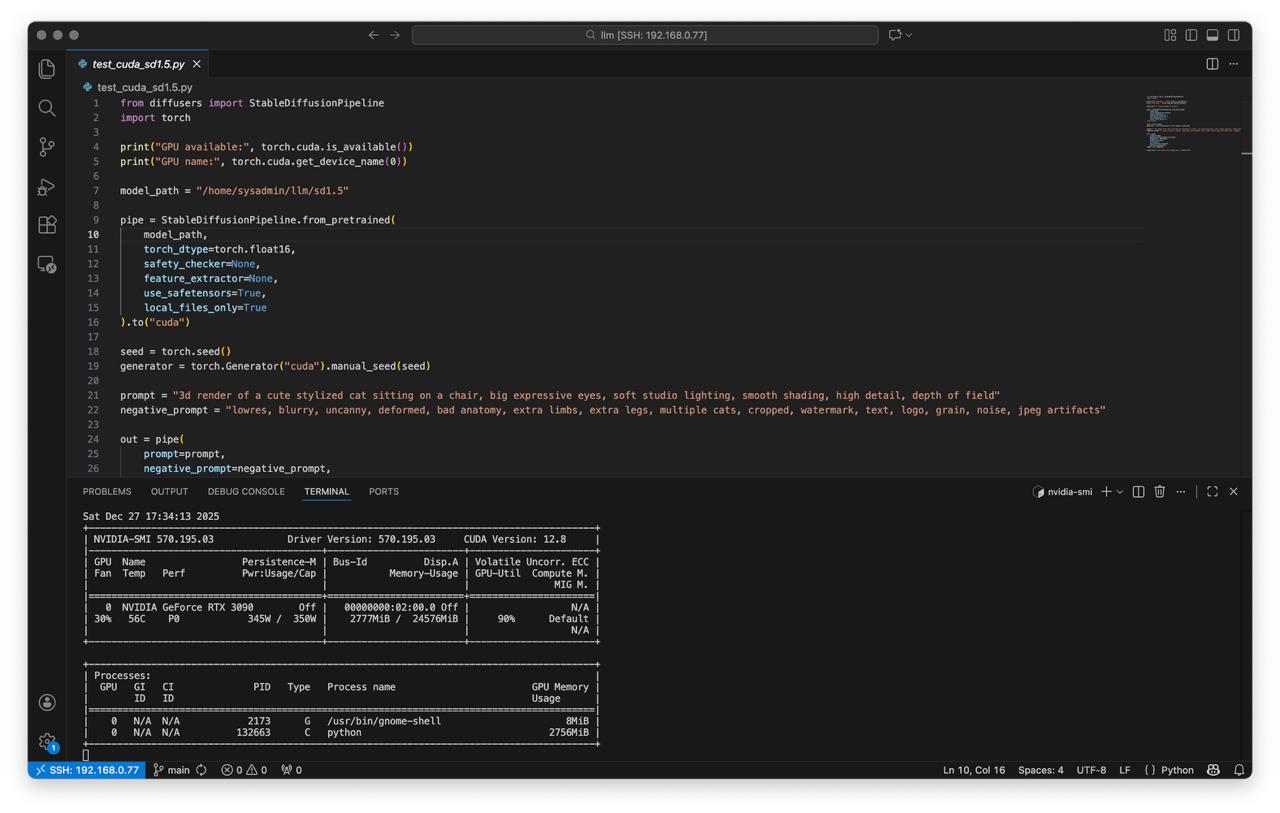

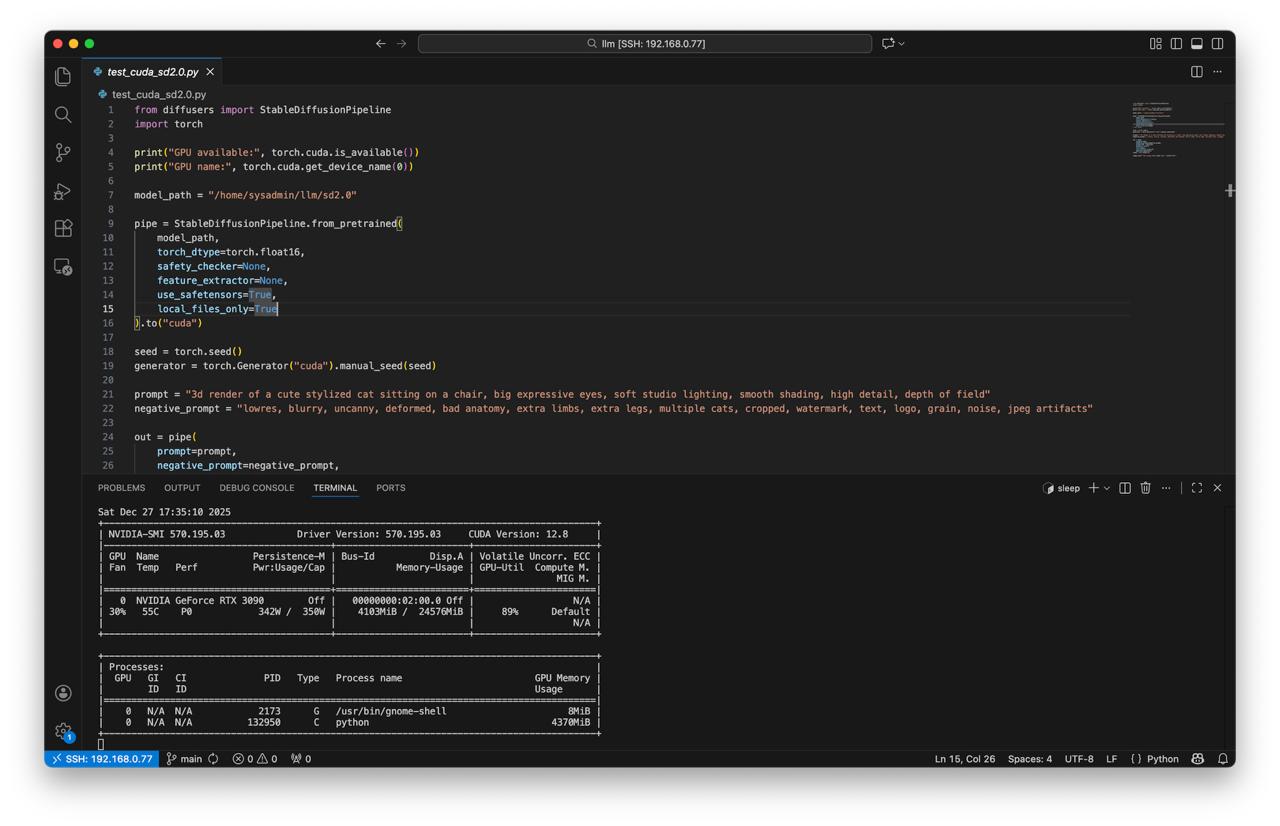

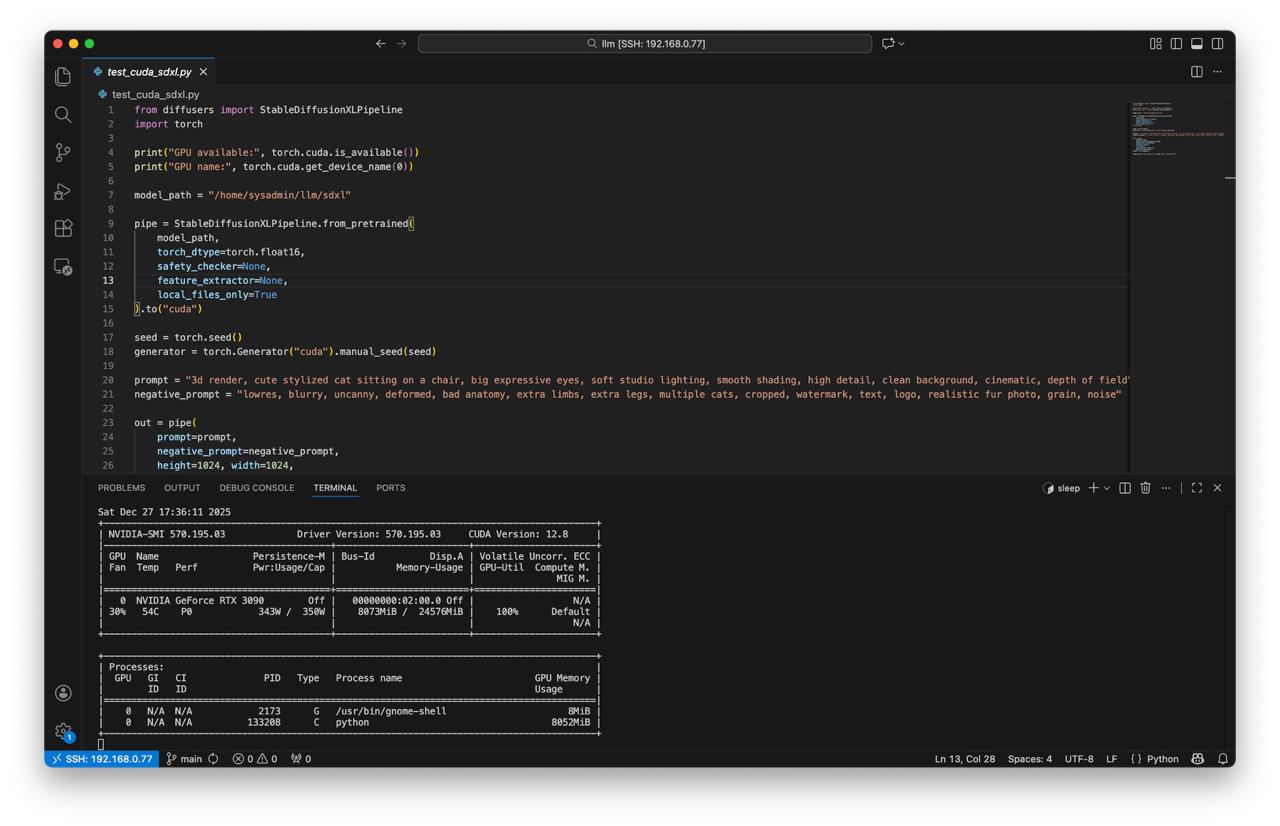
Table of Contents
Overview
Test environment
- Workstation 40 GB RAM, 500GB SSD, 750W Power supply
- Ubuntu 24.04 LTS HWE Kernel
- Install python 3.12
My test environment: HP Z440 + NVIDIA RTX 3090
Instructions
Steps
Preapre python environment for CUDA:
mkdir -p ~/llm && cd ~/llm
python3 -m venv .venv_llm_sd1.5
source ./.venv_llm_sd1.5/bin/activate
python -m pip install --upgrade pip
pip install "torch==2.7.0" "torchvision==0.22.0" "torchaudio==2.7.0" --index-url https://download.pytorch.org/whl/cu128
pip install transformers accelerate diffusers safetensors
Get the the StableDiffusion
- Get SD1.5
git lfs install
git clone https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5 sd1.5
- Get SD2.0
git lfs install
git clone https://huggingface.co/sd2-community/stable-diffusion-2 sd2.0
- Get SDXL
git lfs install
git clone https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0 sdxl
Create script test_cuda_sd1.5.py:
from diffusers import StableDiffusionPipeline
import torch
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_path = "/home/sysadmin/llm/sd1.5"
pipe = StableDiffusionPipeline.from_pretrained(
model_path,
torch_dtype=torch.float16,
safety_checker=None,
feature_extractor=None,
use_safetensors=True,
local_files_only=True
).to("cuda")
seed = torch.seed() # 4619748823278046644
generator = torch.Generator("cuda").manual_seed(seed)
prompt = "3d render of a cute stylized cat sitting on a chair, \
big expressive eyes, soft studio lighting, \
smooth shading, high detail, depth of field"
negative_prompt = "lowres, blurry, uncanny, deformed, \
bad anatomy, extra limbs, extra legs, multiple cats, \
cropped, watermark, text, logo, grain, noise, jpeg artifacts"
out = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=512, width=512,
guidance_scale=9,
clip_skip=1,
num_inference_steps=50,
generator=generator)
image = out.images[0]
image.save(f"test_image_sd15_{seed}.png", format="PNG")
- Run test
python test_cuda_sd1.5.py
Create script test_cuda_sd2.0.py:
from diffusers import StableDiffusionPipeline
import torch
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_path = "/home/sysadmin/llm/sd2.0"
pipe = StableDiffusionPipeline.from_pretrained(
model_path,
torch_dtype=torch.float16,
safety_checker=None,
feature_extractor=None,
use_safetensors=True,
local_files_only=True
).to("cuda")
seed = torch.seed() # 885271215860566002
generator = torch.Generator("cuda").manual_seed(seed)
prompt = "3d render of a cute stylized cat sitting \
on a chair, big expressive eyes, soft studio lighting, \
smooth shading, high detail, depth of field"
negative_prompt = "lowres, blurry, uncanny, deformed, \
bad anatomy, extra limbs, extra legs, multiple cats, \
cropped, watermark, text, logo, grain, noise, jpeg artifacts"
out = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=768, width=768,
guidance_scale=8,
clip_skip=1,
num_inference_steps=45,
generator=generator)
image = out.images[0]
image.save(f"test_image_sd20_{seed}.png", format="PNG")
- Run test
python test_cuda_sd2.0.py
Create script test_cuda_sdxl.py:
from diffusers import StableDiffusionXLPipeline
import torch
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_path = "/home/sysadmin/llm/sdxl"
pipe = StableDiffusionXLPipeline.from_pretrained(
model_path,
torch_dtype=torch.float16,
safety_checker=None,
feature_extractor=None,
local_files_only=True
).to("cuda")
seed = torch.seed()
generator = torch.Generator("cuda").manual_seed(seed)
prompt = "3d render, cute stylized cat sitting on \
a chair, big expressive eyes, soft studio lighting, \
smooth shading, high detail, clean background, \
cinematic, depth of field"
negative_prompt = "lowres, blurry, uncanny, deformed, \
bad anatomy, extra limbs, extra legs, multiple cats, \
cropped, watermark, text, logo, realistic fur photo, \
grain, noise"
out = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=1024, width=1024,
guidance_scale=5,
clip_skip=1,
num_inference_steps=45,
generator=generator)
image = out.images[0]
image.save(f"test_image_sdxl_{seed}.png", format="PNG")
- Run test
python test_cuda_sdxl.py