Date: 31.01.2026
Qwen Image CUDA PyTorch BNB4 Test


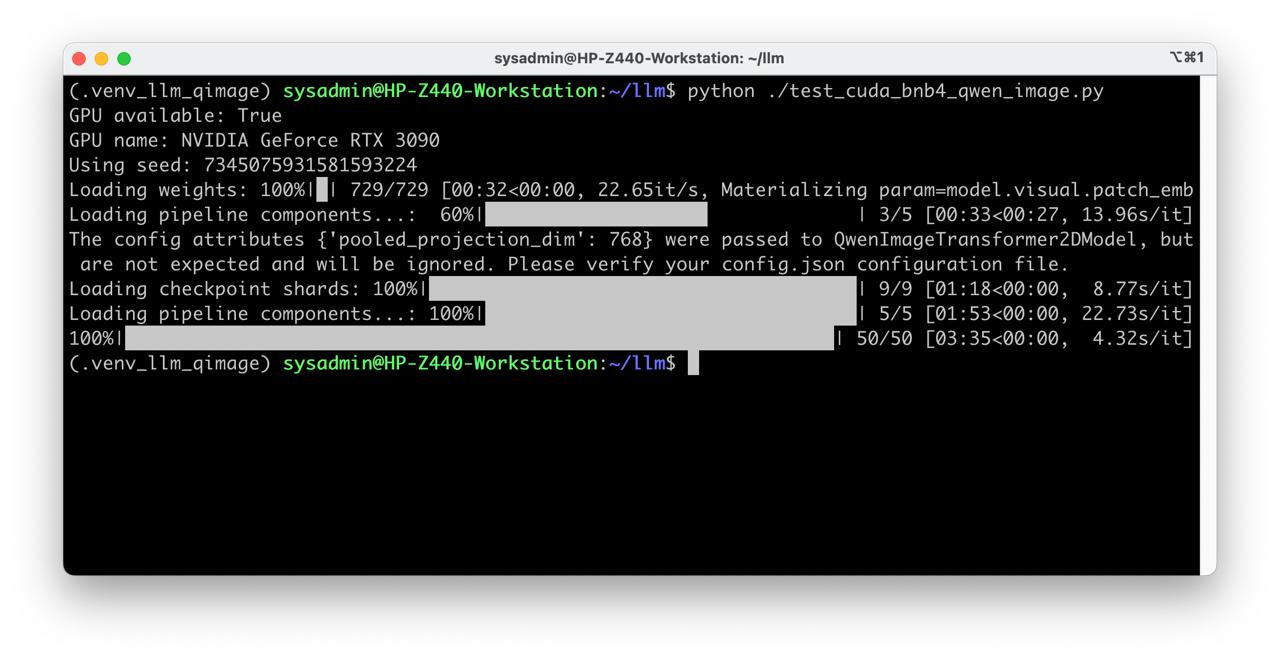
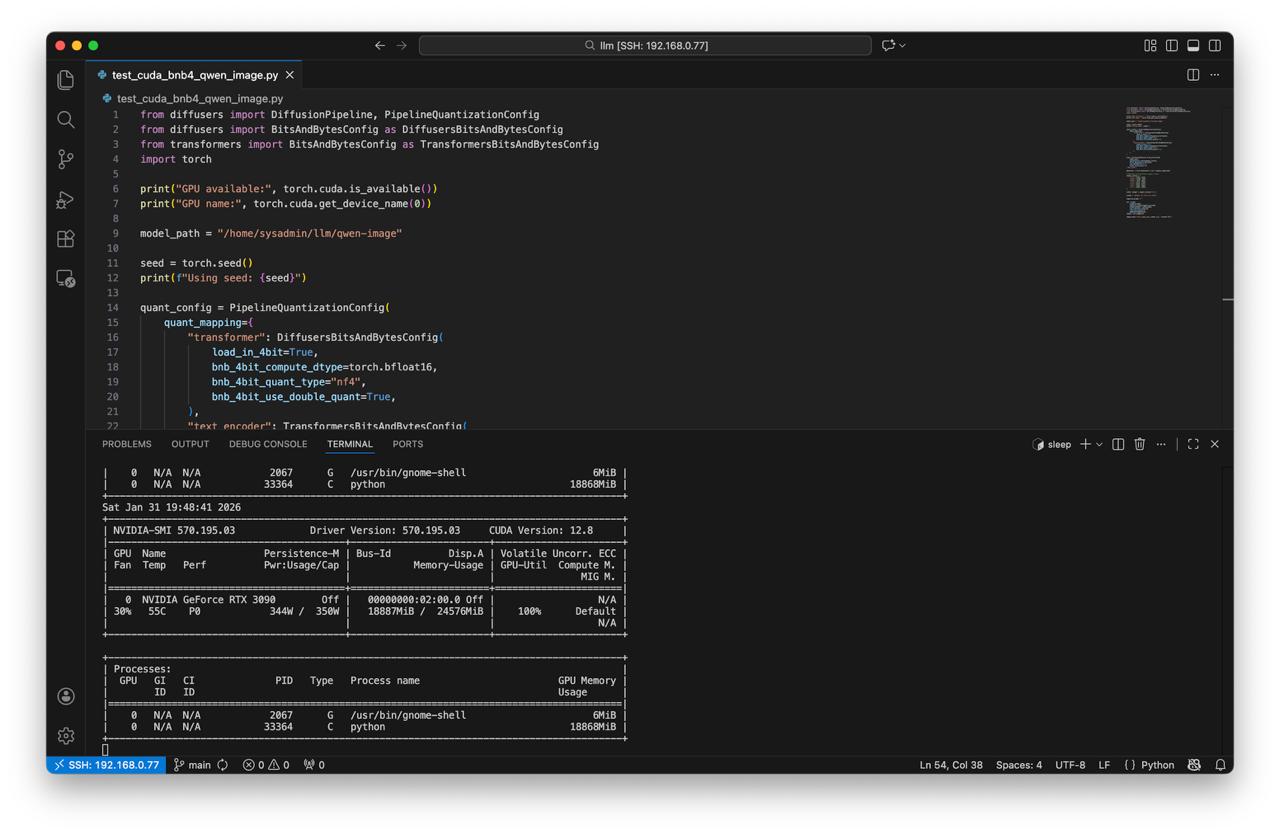
Table of Contents
Overview
Test environment
- Workstation 40 GB RAM, 500GB SSD, 750W Power supply
- Ubuntu 24.04 LTS HWE Kernel
- Install python 3.12
My test environment: HP Z440 + NVIDIA RTX 3090
Instructions
Ubuntu preparation
sudo apt-get install --install-recommends linux-generic-hwe-24.04
hwe-support-status --verbose
sudo apt dist-upgrade
sudo reboot
Driver setup
- Install drivers nvidia-driver-570
sudo apt install nvidia-driver-570 clinfo
sudo reboot
- Check installation
nvidia-smi
clinfo
- Install dev tools
sudo apt install -y python3-venv python3-dev git git-lfs
Check CUDA in Python
- Preparing PyTorch
mkdir -p ~/llm && cd ~/llm
python3 -m venv .venv_llm_qimage
source ./.venv_llm_qimage/bin/activate
python -m pip install --upgrade pip
pip install "torch==2.7.1" "torchvision==0.22.1" "torchaudio==2.7.1" --index-url https://download.pytorch.org/whl/cu128
pip install "bitsandbytes==0.46.1"
pip install transformers accelerate diffusers safetensors
python3 -c "import torch; print(torch.__version__); print(torch.cuda.is_available());print(torch.cuda.get_device_name(0));"
- Expected response
2.7.0+cu128
True
NVIDIA GeForce RTX 3090
- Check BitsAndBytes installation
python -m bitsandbytes
Dry run
Get the Qwen Image
git lfs install
git clone https://huggingface.co/Qwen/Qwen-Image qwen-image
Create script test_cuda_bnb4_qwen_image.py:
from diffusers import DiffusionPipeline, PipelineQuantizationConfig
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
import torch
print("GPU available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0))
model_path = "/home/sysadmin/llm/qwen-image"
seed = torch.seed()
print(f"Using seed: {seed}")
quant_config = PipelineQuantizationConfig(
quant_mapping={
"transformer": DiffusersBitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
),
"text_encoder": TransformersBitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
),
}
)
pipe = DiffusionPipeline.from_pretrained(
model_path,
quantization_config=quant_config,
torch_dtype=torch.bfloat16,
use_safetensors=True,
local_files_only=True
).to("cuda")
generator = torch.Generator("cuda").manual_seed(seed)
# Generate with different aspect ratios
aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472),
"3:2": (1584, 1056),
"2:3": (1056, 1584),
}
width, height = aspect_ratios["1:1"]
prompt = "ginger cat sits on a chair"
negative_prompt = ""
out = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=height, width=width,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=generator)
image = out.images[0]
image.save(f"test_image_qwen_{seed}.png", format="PNG")
Run test
Check
nvidia-smiduring the testwatch -n 1 nvidia-smi
- With quantization 4bit
python ./test_cuda_bnb4_qwen_image.py
Enjoy the result!
- It works but flaky, time to time OOM