Date: 26.08.2025
Vulkan llama.cpp in Docker Test
In this articale detailed described how to run llama.cpp with Vulkan in docker container. Tested LLM Mathstral.
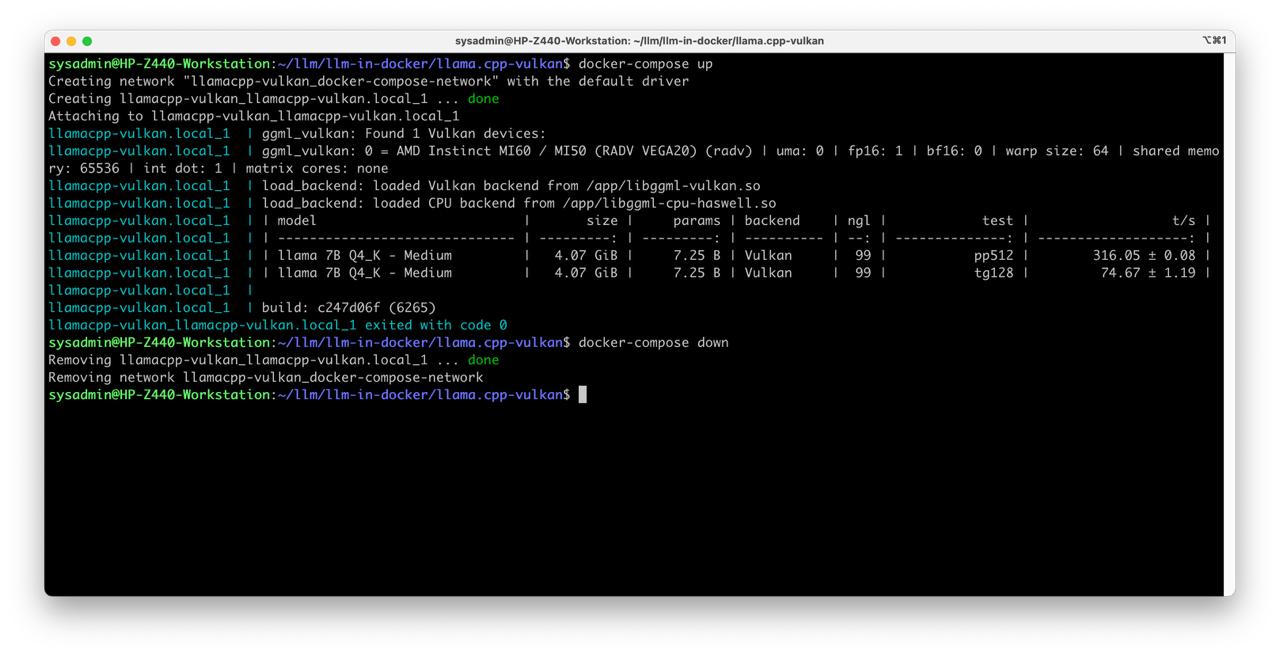
Table of Contents
Overview
Requirments
- AMD Mi50/MI100 32Gb VRAM
- Workstation 40 GB RAM, 500GB SSD, 750W Power supply
- Ubuntu 24.04 LTS
- Docker CE
My test environment: HP Z440 + AMD Mi50 32gb
Instructions
Steps
Get the Mathstral GGUF for test
git lfs install
git clone https://huggingface.co/lmstudio-community/mathstral-7B-v0.1-GGUF mathstral
Run llama.cpp with Vulkan in Docker Compose
Prepare docker-compose.yaml for AMD ROCm
To run llama.cpp in docker we will use docker-compose orchestration to make deploy more clear.
Main docker compose orchestration steps
- Pull llama.cpp docker image for Vulkan
- Enable port forwarding for application to docker host
- Mount AMD driver devices to container
- Add AMD ROCm groups to container user
- Mount folder with LLM Mathstral
- Create local network just in case
version: "3.3"
services:
llamacpp-vulkan.local:
image: ghcr.io/ggml-org/llama.cpp:full-vulkan
entrypoint:
- /bin/bash
- -c
- |
#/app/llama-server --list-devices
/app/llama-server -m /models/mathstral/mathstral-7B-v0.1-Q4_K_M.gguf \
--chat-template llama2 --port 8080 --host 0.0.0.0 \
--device Vulkan0 --n-gpu-layers 999
ports:
- "8080:8080"
environment:
TZ: "Etc/GMT"
LANG: "C.UTF-8"
ipc: host
devices:
- /dev/kfd
- /dev/dri
group_add:
- "${RENDER_GID}"
- "${VIDEO_GID}"
volumes:
- ../mathstral:/models/mathstral
networks:
- docker-compose-network
networks:
docker-compose-network:
ipam:
config:
- subnet: 172.24.24.0/24
Run Mistral in Docker and make a test request
- Deploy docker compose
echo "RENDER_GID=$(getent group render | cut -d: -f3)" > .env
echo "VIDEO_GID=$(getent group video | cut -d: -f3)" >> .env
docker-compose up
- Check logs
docker docker container logs llamacpp-vulkan_llamacpp-vulkan.local_1
- Test request
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "",
"messages": [{"role": "user", "content": "Continue this text: What you know about sun?"}],
"max_tokens": 360,
"temperature": 0.7,
"top_p": 0.95,
"stop": "eof"
}' | jq
- Stop docker container
docker-compose down
Benchmark
To run benchmark, replace the command in the entrypoint of docker compose with this
/app/llama-bench -m /models/mathstral/mathstral-7B-v0.1-Q4_K_M.gguf
and deploy docker compose
Enjoy the result
All project avalible on github