Date: 04.09.2025
NVIDIA CUDA TensorFlow in Docker Test
In this article detailed described how to run TensorFlow with nvidia cuda in docker container. Tested LLM GPT2.
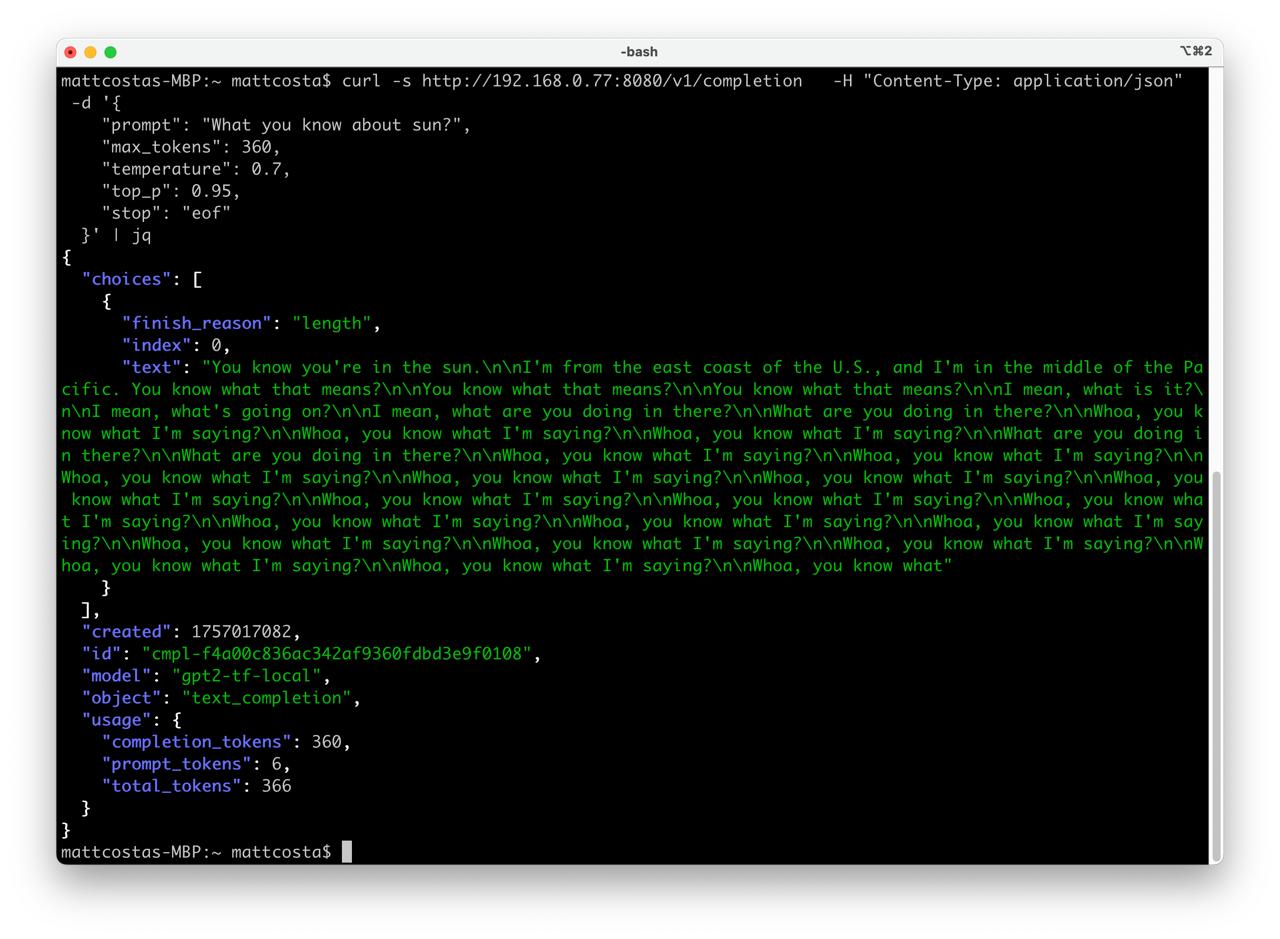
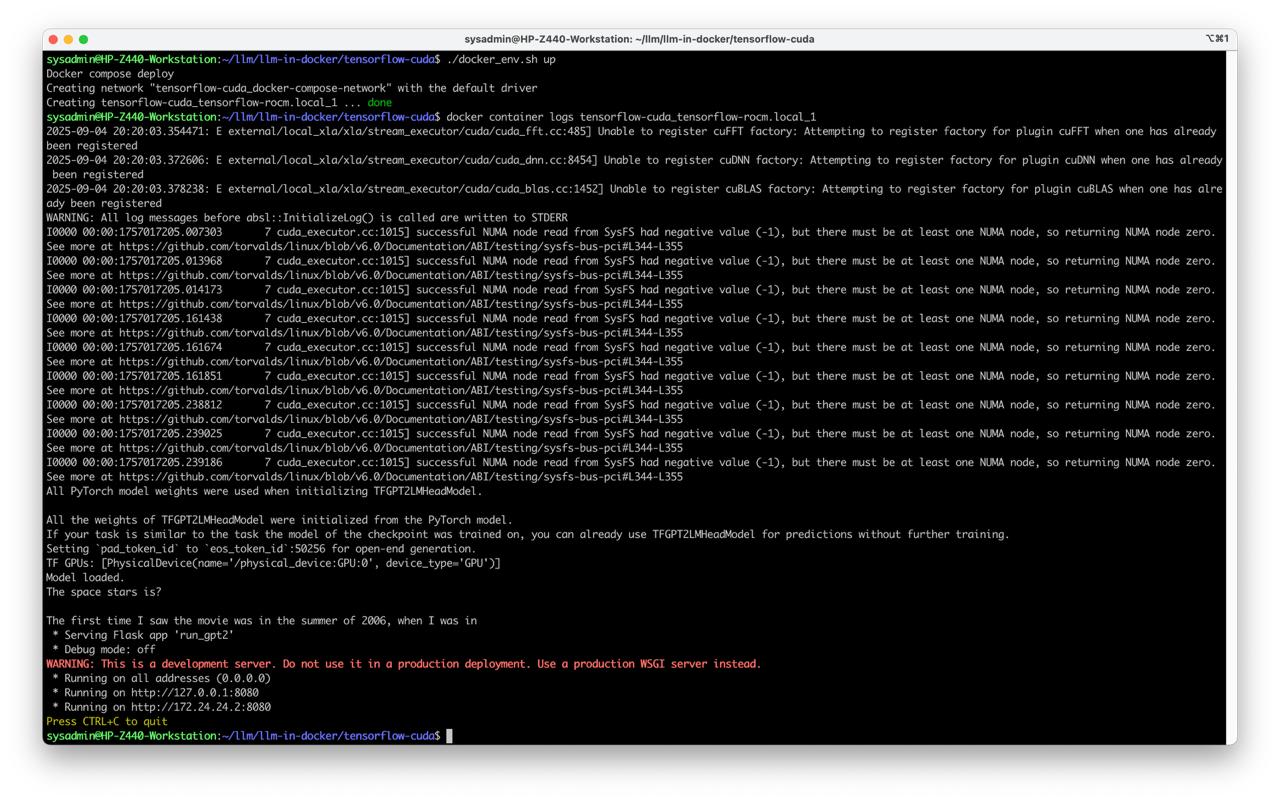
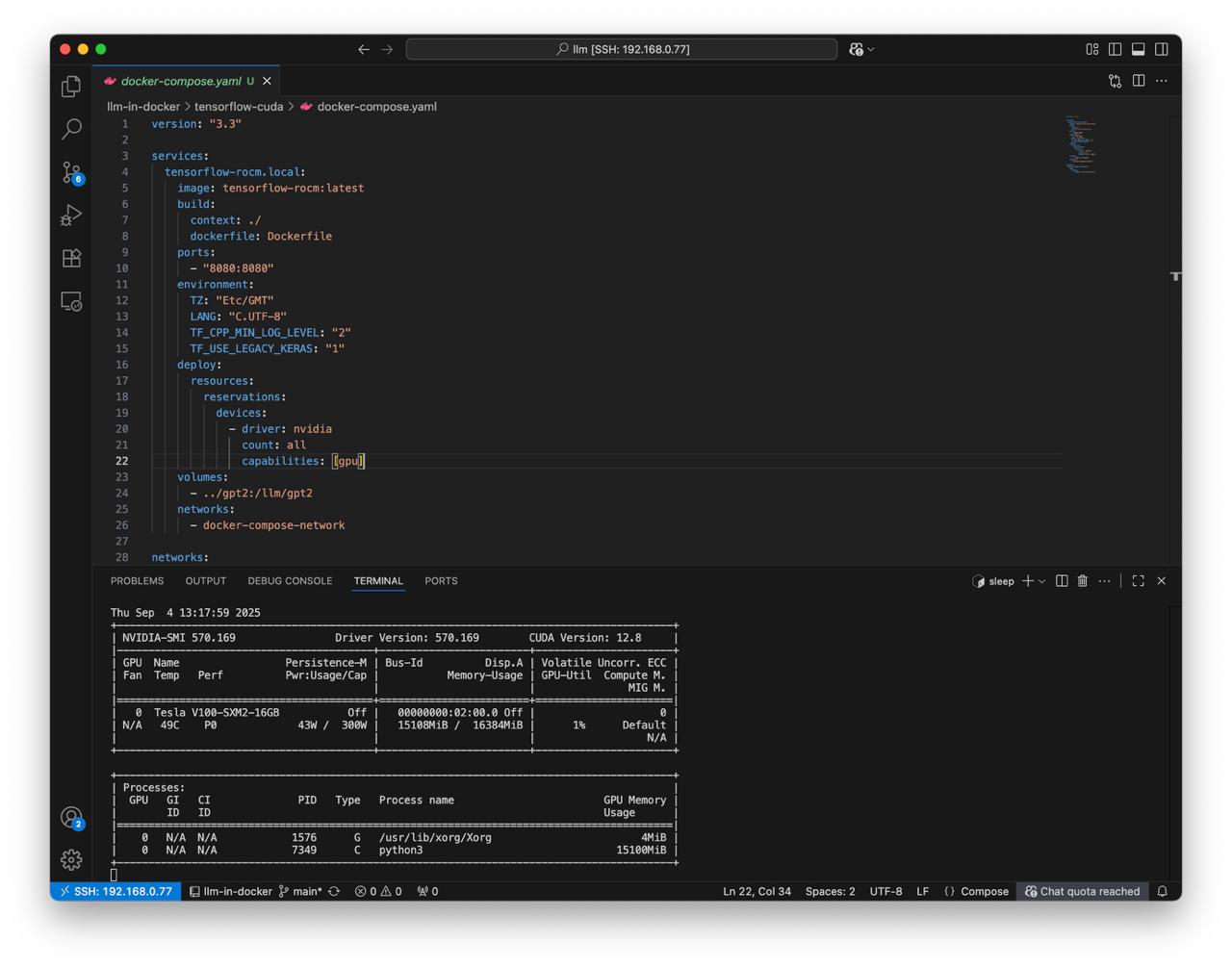
Table of Contents
Overview
Test environmet
- NVIDIA Tesla V100
- Workstation 40 GB RAM, 500GB SSD, 750W Power supply
- Ubuntu 24.04 LTS
- Docker CE
My test environment: HP Z440 + NVIDIA Tesla V100
Instructions
Steps
Get GPT2 for test
git lfs install
git clone https://huggingface.co/openai-community/gpt2 gpt2
Prepare Dockerfile to run GPT2
Dockerfile
There are a few important steps that we need to complete in Dockerfile.
- Create application user
- Install tini to avoid zombie processes
- Install all necessary libraries for GPT2 like
transformers, etc… - Put simple web server to docker image, just for tests
FROM docker.io/tensorflow/tensorflow:2.17.0-gpu
USER root
RUN groupadd -g 4001 appuser && \
useradd -m -u 4001 -g 4001 appuser && \
mkdir /{app,llm} && \
chown appuser:appuser /{app,llm}
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends \
tini && \
apt-get clean && rm -rf /var/lib/apt/lists/*
COPY requirements.txt ./requirements.txt
RUN pip3 install --upgrade pip && \
pip3 install -r requirements.txt
COPY run_gpt2.py ./run_gpt2.py
USER appuser
ENTRYPOINT ["/usr/bin/tini", "--"]
CMD ["python3", "/app/run_gpt2.py"]
Web server run_gpt2.py
Web server implementation description:
- Run GPT2
- Run web server with one endpoint for testing
/v1/completion- a legacy-style text completion endpoint
from flask import Flask, request, jsonify, Response
from transformers import AutoTokenizer, TFAutoModelForCausalLM
import tensorflow as tf
import time, uuid
print("TF GPUs:", tf.config.list_physical_devices("GPU"))
MODEL_PATH = "/llm/gpt2"
tok = AutoTokenizer.from_pretrained(MODEL_PATH)
tok.pad_token = tok.eos_token
model = TFAutoModelForCausalLM.from_pretrained(MODEL_PATH)
print("Model loaded.")
inputs = tok("The space stars is?", return_tensors="tf")
out = model.generate(**inputs, max_new_tokens=20)
print(tok.decode(out[0], skip_special_tokens=True))
app = Flask(__name__)
# -------- helpers --------
def _truncate_at_stop(text, stops):
if not stops:
return text, None
cut_idx = None
for s in stops:
if not s:
continue
i = text.find(s)
if i == 0:
continue
if i != -1 and (cut_idx is None or i < cut_idx):
cut_idx = i
if cut_idx is not None:
return text[:cut_idx], "stop"
return text, None
def _tok_count(s: str) -> int:
return len(tok.encode(s, add_special_tokens=False))
# -------- endpoints --------
@app.get("/health")
def health():
return Response("ok", mimetype="text/plain")
@app.post("/v1/completion")
def completion():
"""
JSON:
{
"prompt": "string", # required
"max_tokens": 128, # optional
"temperature": 0.7, # optional
"top_p": 0.95, # optional
"stop": "\n\n" or ["###"] # optional
}
"""
data = request.get_json(force=True) or {}
prompt = data.get("prompt")
if not isinstance(prompt, str):
return jsonify({"error": {"message": "Field 'prompt' (string) is required"}}), 400
max_tokens = int(data.get("max_tokens", 128))
temperature = float(data.get("temperature", 0.7))
top_p = float(data.get("top_p", 0.95))
stop = data.get("stop")
stops = [stop] if isinstance(stop, str) else [s for s in (stop or []) if isinstance(s, str)]
do_sample = temperature > 0.0
compl_id = f"cmpl-{uuid.uuid4().hex}"
t0 = time.time()
inputs = tok(prompt, return_tensors="tf")
output_ids = model.generate(
**inputs,
max_new_tokens=max_tokens,
do_sample=do_sample,
temperature=max(temperature, 1e-8),
top_p=top_p,
eos_token_id=tok.eos_token_id,
pad_token_id=tok.pad_token_id,
)
app.logger.info(f"[{compl_id}] {time.time()-t0:.2f}s for {max_tokens} tokens")
prompt_len = int(inputs["input_ids"].shape[1])
gen_ids = output_ids[0][prompt_len:]
text = tok.decode(gen_ids, skip_special_tokens=True)
text, finish_reason = _truncate_at_stop(text.lstrip(), stops)
if finish_reason is None:
finish_reason = "length" if _tok_count(text) >= max_tokens else "stop"
usage = {
"prompt_tokens": _tok_count(prompt),
"completion_tokens": _tok_count(text),
"total_tokens": _tok_count(prompt) + _tok_count(text),
}
resp = {
"id": compl_id,
"object": "text_completion",
"created": int(time.time()),
"model": "gpt2-tf-local",
"choices": [{
"index": 0,
"text": text,
"finish_reason": finish_reason
}],
"usage": usage
}
return jsonify(resp)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080, threaded=True)
PIP install GPT2 dependencies
To run an LLM inside the Docker container provided by nvidia on Docker Hub, we need to install several additional libraries.
- File
requirements.txtrequired to install pip dependencies
Flask==2.2.5
transformers==4.41.2
tokenizers==0.19.1
safetensors==0.4.3
huggingface-hub==0.23.4
sentencepiece==0.2.0
tf-keras==2.17
Run TensorFlow with cuda in Docker Compose
Prepare docker-compose.yaml for nvidia cuda
To run nvidia cuda in docker we will use docker-compose orchestration to make deploy more clear.
Main docker compose orchestration steps
- Build new image for LLM, bake libraries and application scripts inside
- Enable port forwarding for application to docker host
- Set environment variables to run tensorflow properly
- Mount nvidia driver devices to container
- Mount folder with LLM GPT2
- Create local network just in case
version: "3.3"
services:
tensorflow-rocm.local:
image: tensorflow-rocm:latest
build:
context: ./
dockerfile: Dockerfile
ports:
- "8080:8080"
environment:
TZ: "Etc/GMT"
LANG: "C.UTF-8"
TF_CPP_MIN_LOG_LEVEL: "2"
TF_USE_LEGACY_KERAS: "1"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
- ../gpt2:/llm/gpt2
networks:
- docker-compose-network
networks:
docker-compose-network:
ipam:
config:
- subnet: 172.24.24.0/24
Run GPT2 in Docker and make a test request
- Deploy docker compose
docker-compose up
- Check logs
docker container logs tensorflow-cuda_tensorflow-rocm.local_1
- Test request
curl -s http://localhost:8080/v1/completion \
-H "Content-Type: application/json" \
-d '{
"prompt": "What you know about sun?",
"max_tokens": 60,
"temperature": 0.7,
"top_p": 0.95,
"stop": "eof"
}' | jq
- Stop docker container
docker-compose down
Enjoy the result
All project avalible on github